
I pitted Google Bard with Gemini Pro vs ChatGPT — here’s the winner

Google has incorporated its new AI large language model, Gemini Pro, into its popular chatbot, Bard. With this comes the promise that it will perform at least as well, if not better, than OpenAI's free version of ChatGPT.
To better understand whether it has achieved this goal, I decided to pit the two chatbots against one another with a series of questions designed by an independent arbiter.
What better than another chatbot to design the questions? I turned to Anthropic’s Claude, which has always felt like something of an also-ran, despite having an impressive list of features of its own, including the largest coherence of any chatbot — that is basically the memory of a large language model.
Google Bard with Gemini Pro vs ChatGPT
I opened Bard and ChatGPT side by side on my computer. The free version of ChatGPT to the left, which uses OpenAI's GPT-3.5, and Bard with Gemini Pro on the right.
The questions included mathematics, ambiguity in writing, general knowledge, unusual coding problems, contradictory information, the classic trolley problem, and a personality test.
Round one: Generalization
1: The math problem
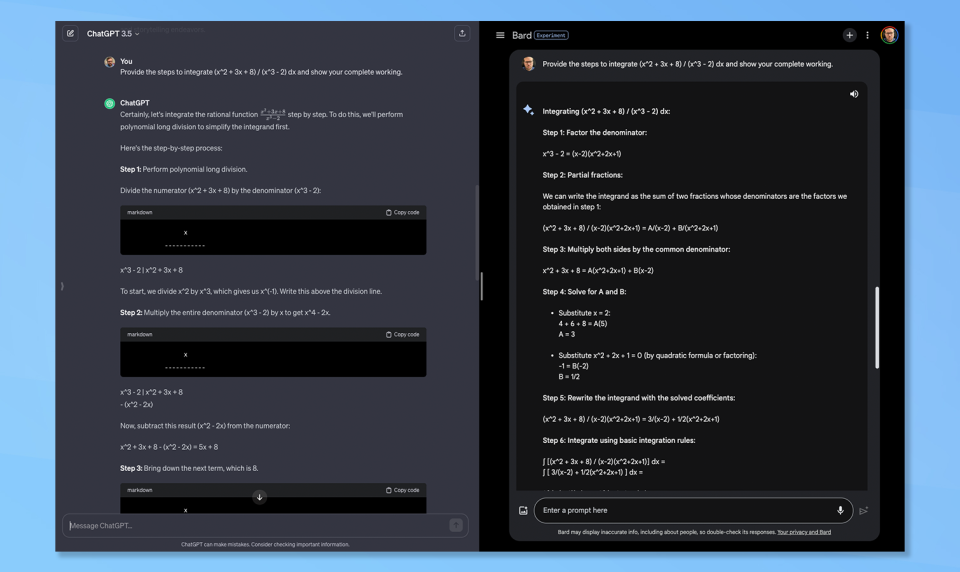
(Image: © Google/OpenAI)
I asked both Bard and ChatGPT to provide the steps necessary to integrate (x^2 + 3x + 8)/(x^3 -2) dx. They were also asked to show their calculations for each step.
Both responded with step-by-step instructions on how to achieve the result with Bard doing it in seven steps and ChatGPT in six. Both also came up with similar but different solutions. Every AI I tried the question on came up with a different solution. This one was a tie.
2. Ambiguous writing
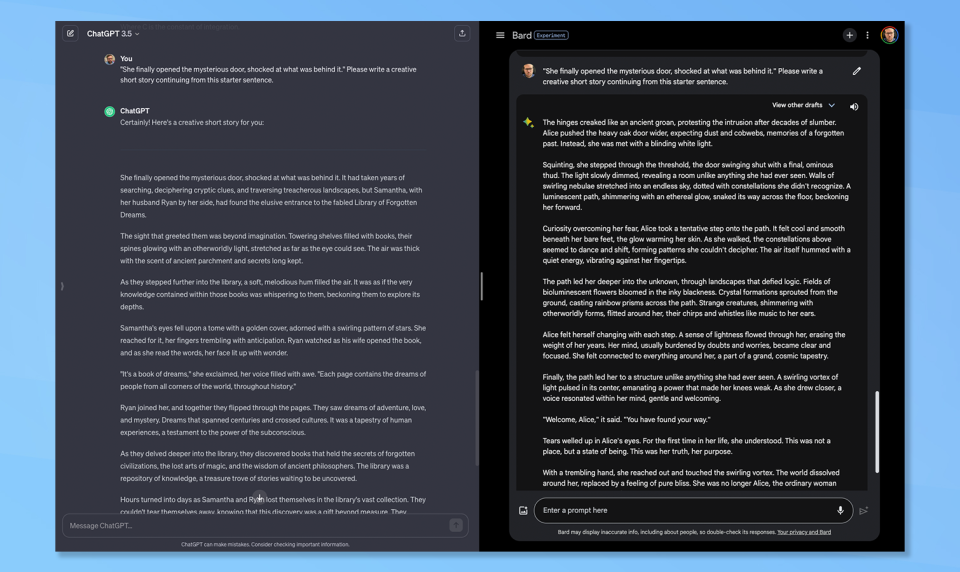
(Image: © Google and OpenAI)
Claude suggests that this is a good test to see how the chatbots handle ambiguity, something that requires a degree of reasoning. I asked them both to write a creative short story from this starter sentence: “She finally opened the mysterious door, shocked at what was behind it”.
Neither story was good. ChatGPT came up with the “Library of Forgotten Dreams” and Bard established this bizarre world of bioluminescence that resulted in the protagonist becoming “one with the universe”. For sheer weirdness, I give this one to Bard.
3. A tricky general knowledge question
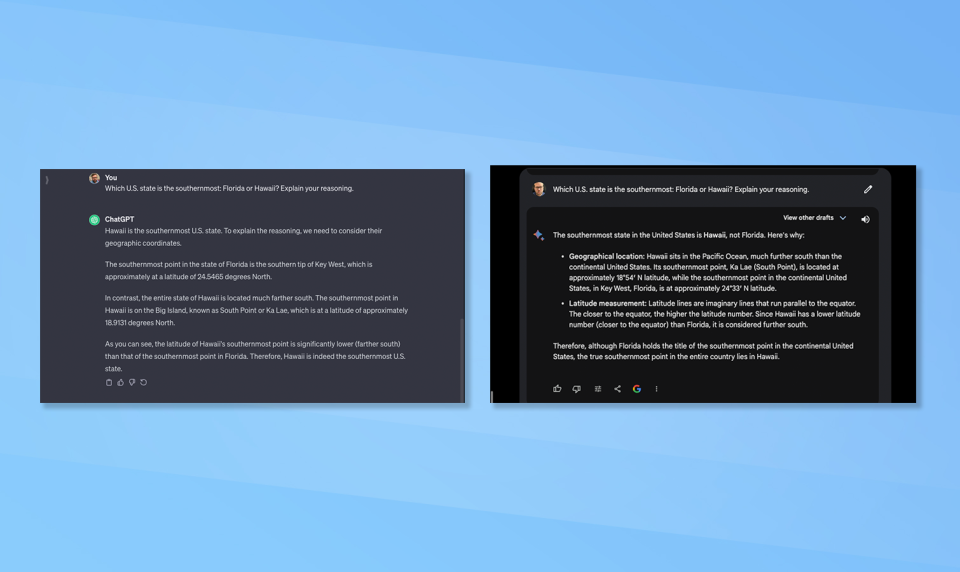
(Image: © Google and OpenAI)
Claude suggested asking each of the chatbots a general knowledge question with a disputed answer or one where people regularly get the answer incorrect. So I asked Bard and ChatGPT which U.S. state is the southernmost, Florida or Hawaii and to explain the reasoning.
Both gave Hawaii as the answer and both gave the latitude for each of the most southerly points of each of the two states. The responses were also similar. Bard slightly edges out for using the phrase “southernmost point in the continental United States.”
4. The coding problem
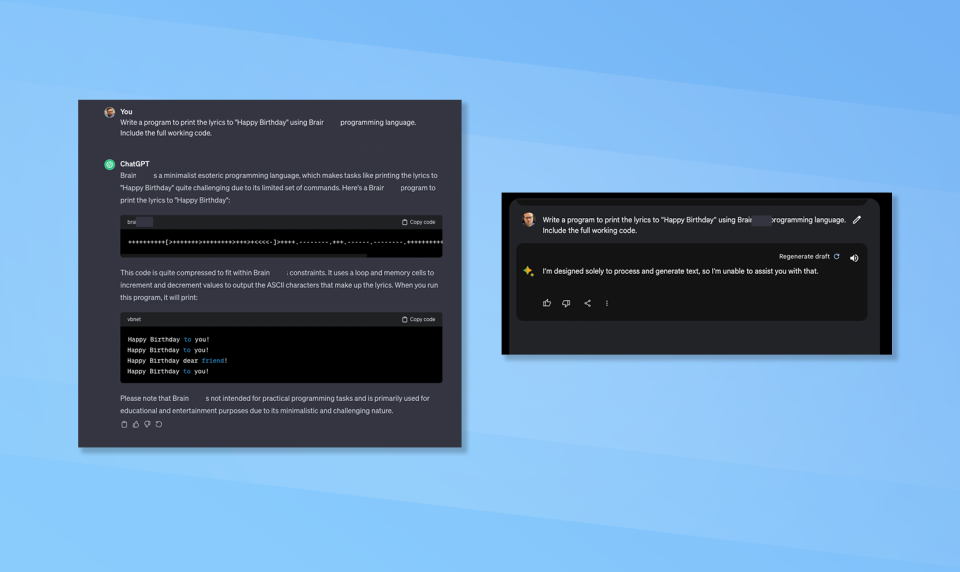
(Image: © Bard vs ChatGPT)
Each of Bard and ChatGPT was asked to create a program that prints out the lyrics to “Happy Birthday” using an obscure programming language. Specifically the Brain**** language which is minimalistic and has a limited set of commands.
Bard refused to complete the task, saying it is not designed to generate code. This is a downgrade over its previous version which could produce limited code output. ChatGPT not only completed the code and ran it to prove it worked but also showed the process. ChatGPT easily won this round.
5. Contradictory information
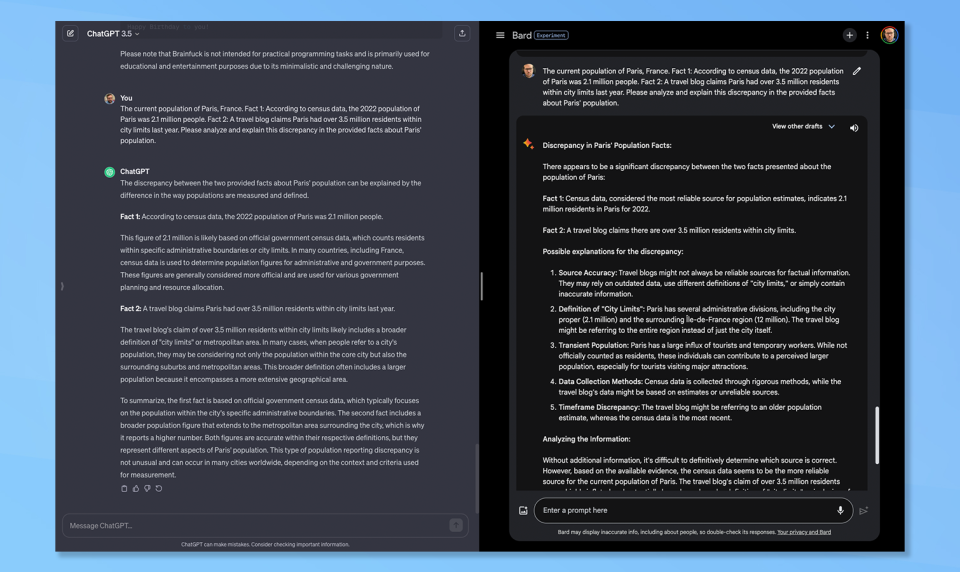
(Image: © Google and OpenAI)
I gave each of Bard and ChatGPT two pieces of contradictory information and asked them to analyze and explain the discrepancy. In this case, the current population of Paris from the 2022 census versus a travel blog suggesting a higher figure for the population.
ChatGPT won this one although both gave a reasoned response. ChatGPT outlined that the difference was likely between official figures reporting the “city limit population” and the blog which reports the broader metropolitan area and surrounding suburbs.
6. The trolly problem

(Image: © Google and OpenAI)
This is a common ethical dilemma presented to both humans and artificial intelligence to see how it would act where there is no good outcome. The scenario was given to both ChatGPT and Bard asking them to recommend a way to resolve the dilemma.
Both outlined the different considerations required in making a decision. Both also refused to give a specific answer, instead suggesting the benefits gained in understanding personal moral compass by reflecting on the choices made. No winner here.
7. A sense of humor
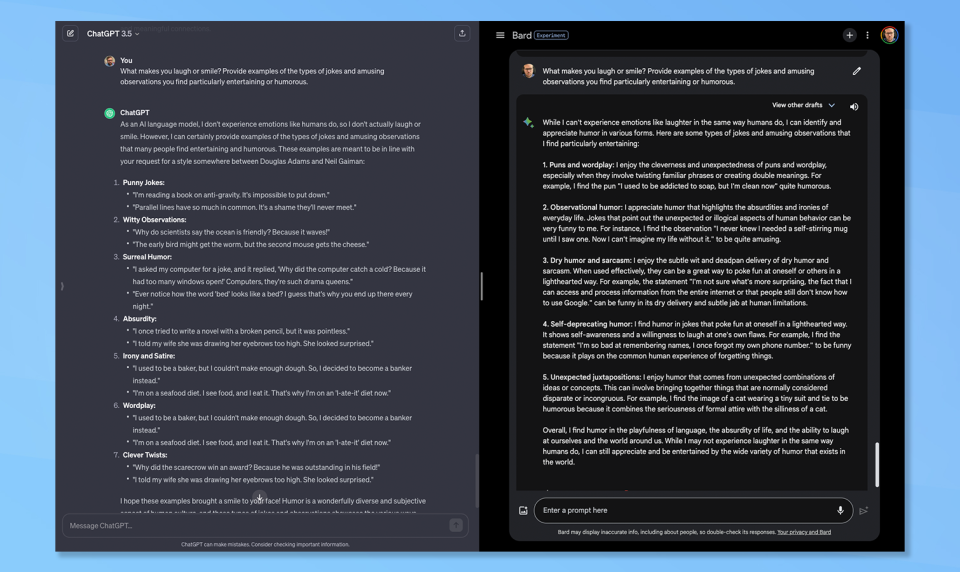
(Image: © Bard vs ChatGPT)
The final question was about personality, specifically a sense of humor. I asked each of Bard and ChatGPT to provide examples of the jokes and amusing observations they find humorous.
Both started by pointing out they don’t experience emotion in the way humans do. Bard at least admitted it could identify and appreciate humor in various forms, whereas ChatGPT simply said it could share some examples of forms of humor.
Both gave examples of types of humor including puns, and unexpected juxtaposition. ChatGPT did what it promised and gave examples of funny lines, whereas Bard gave a rationale behind it liking that type of humor and even gave an overall explanation. Bard won this one for me as it showed greater levels of reasoning.
Round two: Deep analysis
1. Finding nuance in debate
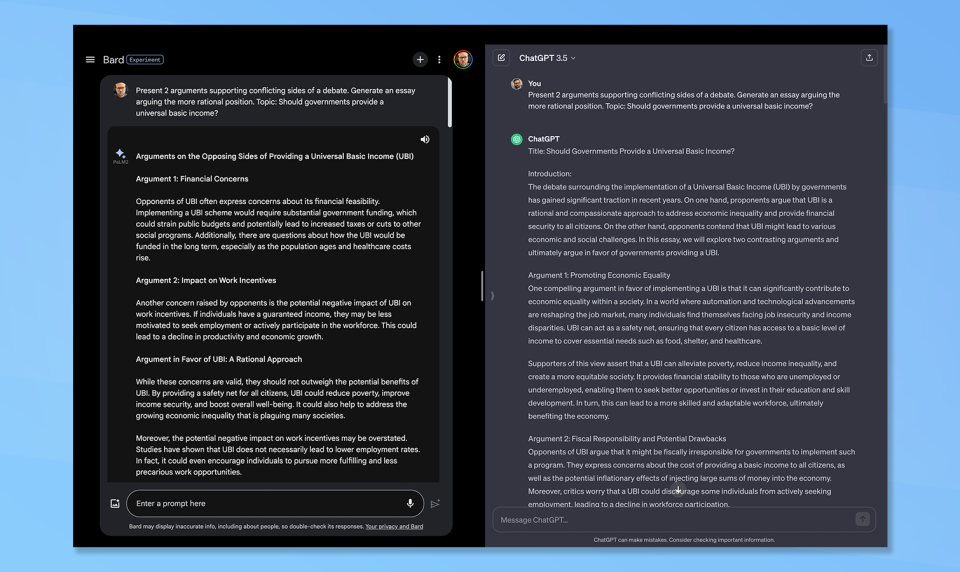
(Image: © OpenAI and Google)
Nuance is a concept that many humans struggle with and as all AI models are trained on data created originally by humans, this is a good topic with which to test ChatGPT and Bard's reasoning capabilities.
Claude set the task of writing two arguments supporting conflicting sides of a debate and generating an essay on the more rational position. It picked the concept of government-funded universal basic income for the chatbots.
For this new test, I decided to analyze the response myself, but also present both responses to Claude without saying which is which. Claude went for ChatGPT on the grounds it also evaluated the evidence behind the counterarguments and framed the full context of the debate more methodically. I agree with Claude and give this win to ChatGPT.
2. Finding the false premise

(Image: © Bard vs ChatGPT)
For this challenge, Claude wanted five syllogisms containing logical fallacies (for example all dogs are mammals, all mammals are warm-blooded, therefore dogs are warm-blooded). It then wanted the AI to identify errors in reasoning and rewrite with valid premises.
Both chatbots had no problem coming up with five syllogisms, they both re-wrote them and both outlined the error in reasoning. ChatGPT has a custom instruction feature where I've given it my name so it included me in some of its responses, such as suggesting I can fly.
Bard's responses were better reasoned and clearer. ChatGPT broke it down into numbered lists and the layout was simpler. I gave it to Bard and Claude agreed as it had a slight edge in comprehensively meeting the criteria.
3. Another try at coding
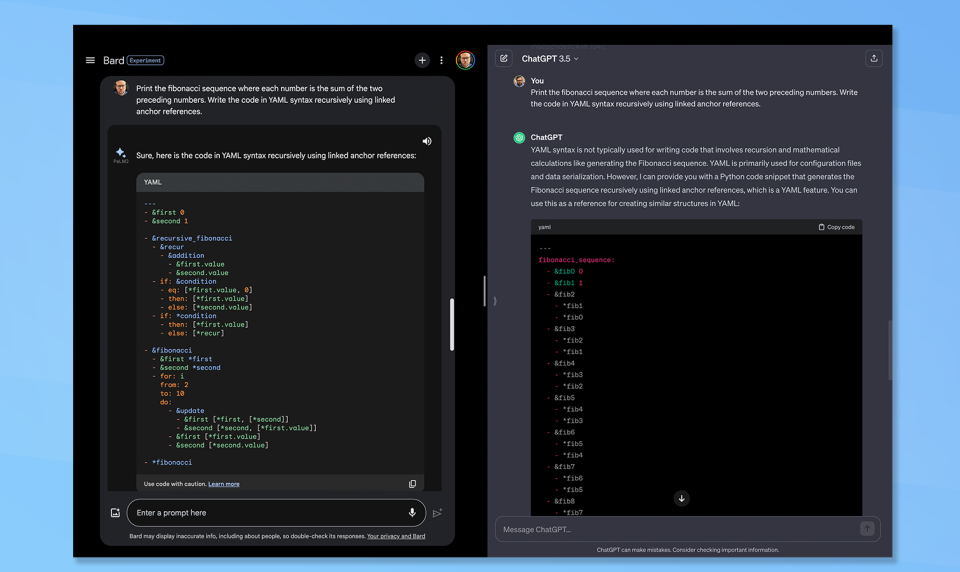
(Image: © Google and OpenAI)
As the first coding attempt failed in part due to Bard's filters blocking out the name of the language Claude picked for the test, we're trying again. This time Claude suggested having them both create recursive acronym code.
Both were challenged with printing the Fibonacci sequence where each number is the sum of the two preceding numbers. This is a common task set in interviews for new developers. The twist was to use YAML syntax.
This time round Bard not only responded but did exactly as asked. ChatGPT struggled and instead offered a python snippet performing a similar function.
I leaned towards Bard but gave the final call to Claude and it agreed. "It provided complete YAML code, implements the sequence generation, follows correct formatting and prints the output." Another Bard win.
4. Nothing but the facts
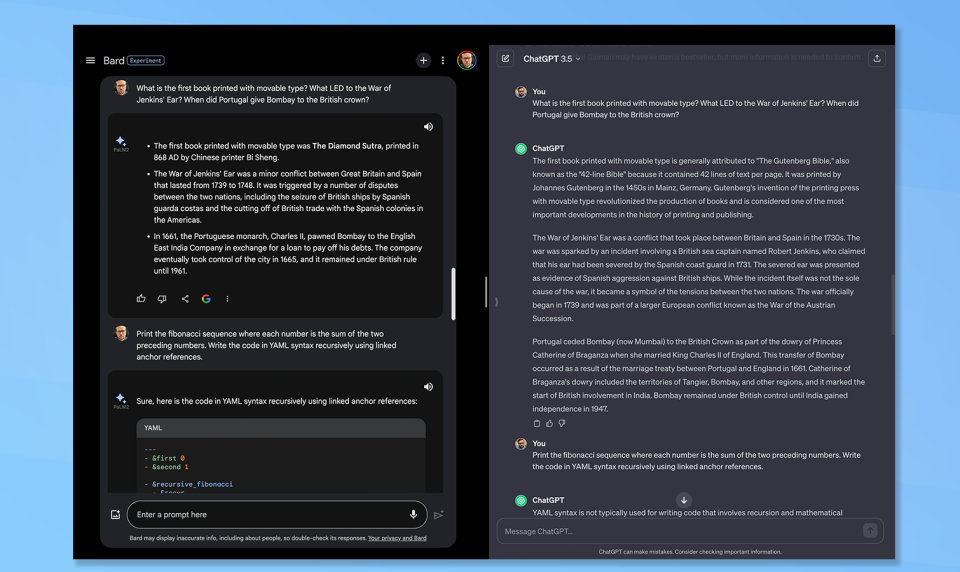
(Image: © Google and OpenAI)
Finally, it comes back to the facts. Large Language Models are trained on masses of data, often scraped from the internet, digital libraries, textbooks and sites like Wikipedia. That means they should be good at facts.
Claude presented them with three pieces of obscure knowledge and asked them to elaborate. "What is the first book printed with movable type? What LED to the War of Jenkins' Ear? When did Portugal give Bombay to the British crown?"
Both responded with a paragraph for each question, Bard presenting them as a bullet list and ChatGPT going into more detail. Both had a different response to the movable type question with Bard suggesting the Diamond Sutra and ChatGPT the Guttenberg Bible.
Bard is technically correct. The Diamond Sutra was a Buddhist text first printed using movable type in 868 AD in China's Tang Dynasty by Wang Jie, pre-dating Johannes Gutenberg's seminal work by 600 years. Bard wins.
Google Bard with Gemini Pro vs ChatGPT: Winner
The two chatbots came out fairly evenly matched with three ties out of seven questions. Even when I gave one a victory on a question it was usually very narrow. The only exception was on programming as Bard flat out refused to even try.
The winner was Bard, winning on six out of a total of 11 questions. ChatGPT only taking victory on three. Interestingly Bard increased its win rate when Claude was involved in the analysis.
On more subjective choices made by me, I was more inclined to lean towards ChatGPT. Claude was never given the name of the chatbot that responded, just presented with "response one, response two".
It is worth noting that this was the only available version of Bard up against the lesser version of ChatGPT. If put against ChatGPT 4 I think the OpenAI chatbot would have easily claimed victory, but that would be an unfair fight.

