
ZeroPoint's nanosecond-scale memory compression could tame power-hungry AI infrastructure
AI is only the latest and hungriest market for high-performance computing, and system architects are working around the clock to wring every drop of performance out of every watt. Swedish startup ZeroPoint, armed with €5 million ($5.5 million USD) in new funding, wants to help them out with a novel memory compression technique at the nanosecond scale — and yes, it's exactly as complicated as it sounds.
The concept is this: losslessly compress data just before it enters RAM, and decompress it afterwards, effectively widening the memory channel by 50% or more just by adding one small piece to the chip.
Compression is, of course, a foundational technology in computing; as ZeroPoint CEO Klas Moreau (left in the image above, with co-founders Per Stenström and Angelos Arelakis) pointed out, "We wouldn't store data on the hard drive today without compressing it. Research suggests 70% of data in memory is unnecessary. So why don't we compress in memory?"
The answer is we don't have the time. Compressing a large file for storage (or encoding it, as we say when it's video or audio) is a task that can take seconds, minutes or hours depending on your needs. But data passes through memory in a tiny fraction of a second, shifted in and out as fast as the CPU can do it. A single microsecond's delay, to remove the "unnecessary" bits in a parcel of data going into the memory system would be catastrophic to performance.
Memory doesn't necessarily advance at the same rate as CPU speeds, though the two (along with lots of other chip components) are inextricably connected. If the processor is too slow, data backs up in memory — and if memory is too slow, the processor wastes cycles waiting on the next pile of bits. It all works in concert, as you might expect.
While super-fast memory compression has been demonstrated, it results in a second problem: Essentially, you have to decompress the data just as fast as you compressed it, returning it to its original state, or the system won't have any idea how to handle it. So unless you convert your whole architecture over to this new compressed-memory mode, it's pointless.
ZeroPoint claims to have solved both of these problems with hyper-fast, low-level memory compression that requires no real changes to the rest of the computing system. You add their tech onto your chip, and it's as if you've doubled your memory.
Although the nitty-gritty details will likely only be intelligible to people in this field, the basics are easy enough for the uninitiated to grasp, as Moreau proved when he explained it to me.
"What we do is take a very small amount of data — a cache line, sometimes 512 bits — and identify patterns in it," he said. "It's the nature of data, that's it's populated with not so efficient information, information that is sparsely located. It depends on the data: The more random it is, the less compressible it is. But when we look at most data loads, we see that we are in the range of two-four times [more data throughput than before]."
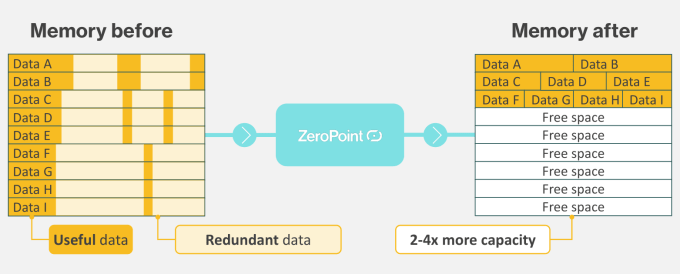
It's no secret that memory can be compressed. Moreau said that everyone in large-scale computing knows about the possibility (he showed me a paper from 2012 demonstrating it), but has more or less written it off as academic, impossible to implement at scale. But ZeroPoint, he said, has solved the problems of compaction — reorganizing the compressed data to be more efficient still — and transparency, so the tech not only works but works quite seamlessly in existing systems. And it all happens in a handful of nanoseconds.
"Most compression technologies, both software and hardware, are on the order of thousands of nanoseconds. CXL [compute express link, a high-speed interconnect standard] can take that down to hundreds," Moreau said. "We can take it down to three or four."
Here's CTO Angelos Arelakis explaining it his way:
https://youtu.be/_IdNOQwqXGc
ZeroPoint's debut is certainly timely, with companies around the globe in quest of faster and cheaper compute with which to train yet another generation of AI models. Most hyperscalers (if we must call them that) are keen on any technology that can give them more power per watt or let them lower the power bill a little.
The primary caveat to all this is simply that, as mentioned, this needs to be included on the chip and integrated from the ground up — you can't just pop a ZeroPoint dongle into the rack. To that end, the company is working with chipmakers and system integrators to license the technique and hardware design to standard chips for high-performance computing.
Of course that is your Nvidias and your Intels, but increasingly also companies like Meta, Google and Apple, which have designed custom hardware to run their AI and other high-cost tasks internally. ZeroPoint is positioning its tech as a cost savings, though, not a premium: Conceivably, by effectively doubling the memory, the tech pays for itself before long.
The €5 million A round just closed was led by Matterwave Ventures, with Industrifonden acting as the local Nordic lead, and existing investors Climentum Capital and Chalmers Ventures chipping in as well.
Moreau said that the money should allow them to expand into U.S. markets, as well as double down on the Swedish ones they are already pursuing.

